
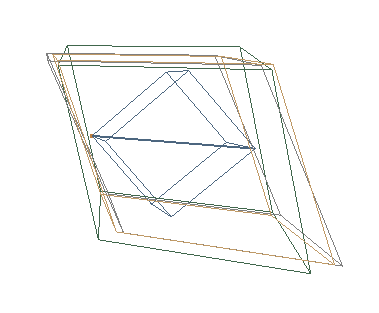
yes this looks like it could be good. However, I am just one coder. This could take quite some time. It is true that a lot of the calculations in the xfer setup are not the most optimal (BC_CModel et al) but these are more to ensure consistency, not speed. The bulk of the time is spent shoveling data from here to there. Surprisingly, one big problem is to decide how big the slices should be, relative to the task setup for the slicer. For a small frame, this overhead is a considerable fraction of time. Pixel format colorspace mapping is done using YUV::yuv. YUV::yuv.rgb_to_yuv_8(r, g, b, y, u, v); YUV::yuv.yuv_to_rgb_8(r, g, b, y, u, v); which is applied in the transfer functions generated by bccmdl.py Insead of using a constant lookup table (lut) that could be changed easily to a pointer, as in yuv->rgb_to_yuv_8 since the lut init already accepts (Kb,Kr) , and can be created and cached pretty easily. The xfer function could use a lut that depends on the demand. On some examination, I found that the number of operational parameters needed makes the colorspace conversion messy: in_cs, out_cs, in_range, out_range, at least... I was up to 6 params when I decided it was too messy to start that day. This is manageable, but I am pretty backed up on projects and problems. The ffmpeg transfer function is great. It has a lot of parameter flexibility and frequently will use asm for the most likely transfers. Even so, It is complex, and can be slower than cin. The colormodel<->AVPixelFormat mapping is good, but not great. When frame data is transmitted between the two, direct moves are used if the mapping is good, and the data is moved twice when an intermediate compatible format is needed . A pretty good idea (which CV/Einar uses, so there is a chunk of code that is already moving this way) might be to abandon the BC_CModels and use AVPixelFormat. Then all transfers could be done with ffmpeg swscale. This puts all of the eggs in the ffmpeg basket, for better or worse. The interface would probably speed up, but all of the plugins and other stuff would need a lot of work. There is a class called LoadBalence (bad name) that creates load client threads that apply a function to a parameter set (usually a slice). Row data is usually best when it is memory cache align, and sequentially/locally processed in non-overlapping chunks. It is hard to imagine that using a more complex schedule would improve throughput. I have not benchmarked the xfer recently, but that may be a good idea to see if thirdparty functions offer help. Permuting/Remapping color components is a really weird idea in the first place, since everything seems to agree on what RGB is, and nobody seems to agree on what YUV is. The attached picture shows an RGB cube (smaller black cube inside the others) and the enclosing YUV cubes for BT601, BT709, and BT2020. The black line in the middle is the white line which goes from YUV(0.0,0.5,0.5) black to YUV(1.0,0.5,0.5) white. As you can see, a bunch of the numerical space is outside of the RGB cube. In fact, since the diagonal of RGB(grey scale) is an axis, it makes the YUV cube approx 2.8 times as large, and so the coverage is really very poor. Almost 2/3 of the YUV colors are not legal RGB values. To much data... morrroww On Tue, Feb 18, 2020 at 11:18 PM Andrew Randrianasulu < randrianasulu@gmail.com> wrote:
Hi, all!
I was looking again at
https://git.cinelerra-gg.org/git/?p=goodguy/cinelerra.git;a=blob;f=cinelerra...
and I think it works (via generated functions from guicast/xfer) by doing pixel-at-a-time, with slices done at different CPUs.
Is there possibility to optionally add few stagin buffesr, so something like http://gegl.org/babl/index.html#Usage will have chance to work?
"The processing operation that babl performs is copying including conversions if needed between linear buffers containing the same count of pixels, with different pixel formats."
So, address calculations usually send down to Cin's own (slow?) functions will be reused to calculate size of buffer (per slice, as done by slicer function), and then babl or ffmpeg or something will transfer pixels to this new buffer, and then .. I dunno, signal 'done' to upper calling function and switch pointers to this new buffer? So, tricking Cin into thinking conversion (per sliced area) was done by its of functions, yet using different set of them (not those row-based macro expanded functions I see in build tree)? As long as pixels organized the same (row x column), and internally represented by same datatypes (like, first 4 bytes is R in float, second is G, third is B, and last 4 bytes is alpha ... for total of 16 bytes per pixel) this should work? Or I missed something? -- Cin mailing list Cin@lists.cinelerra-gg.org https://lists.cinelerra-gg.org/mailman/listinfo/cin
{kind=link}